(LORA) LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS and Quntazied LoRA
LoRA
Paper’s Objective
LoRA, which freezes the pre-trained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture, greatly reducing the number of trainable parameters for downstream tasks. Despite having fewer trainable parameters, a higher training throughput, and, unlike adapters, no additional inference latency.
Central Idea
The weights of the pre-trained model are frozen for example in the self-attention layer of the encoder we have matrix \(W_q\) which is of size \(d \times k\), The hypothesis that the authors have is that instead of adjusting the weights of \(W\) we keep it fixed and learn a \(\Delta W\) which can be further decomposed into \(A\) and \(B\) such that \(\Delta W = A \times B\) where \(A\) is of size \(d \times r\) and \(B\) is of size \(r \times k\) where \(r\) is the rank of the matrix \(\Delta W\). The hypothesis here is that the gradient update matrixes are rank deficient and can be decomposed into low rank matrices. Empirically, the authors show that the very low values like \(r=1\) or \(2\) also works.
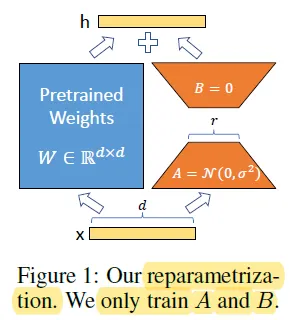
Matrix A is initialized with gaussian random values and matrix B is initialized with the zeros so intially \(\Delta W\) is zero and the model is the same as the pre-trained model. We then scale \(\Delta W x\) by where \(\alpha\) is a constant in \(r\). When optimizing with Adam, tuning \(\alpha\) is roughly the same as tuning the learning rate if we scale the initialization appropriately. As a result, we simply set \(\alpha\) to the first \(r\) we try and do not tune it.
When deployed in production, we can explicitly compute and store \(W = W_0 + BA\) and perform inference as usual. Note that both \(W_0\) and \(BA\) are in \mathbb{R}^{d \times k}. When we need to switch to another downstream task, we can recover \(W_0\) by subtracting \(BA\) and then adding a different \(B_0A_0\) , a quick operation with very little memory overhead.
QLoRA
It is similar to lora but the idea here is that instead of using the full model we will be using the quantized version of the model and train the lora weights. This not as straing forward as it looks there are a few nueonces to the method which I have listed down below. The idea of the QLoRA is trade-off time for memory.
1. First we qunatize the model into 4-bit(Normal Float) store it.
2. We use LoRA 32 bit parameters that we will train and inject them in model
3. We dequnatize the model weights (trade off ) to computation data type(16 bit Brainfloat bfloat) to perform the forward and backward pass but only calculate gradient for the LoRA weights.
LoRA weight helps model in redusing qutizatin errors so if 0.5678 become 0.6 then the error is 0.0322 as our LoRA weights are in 32 bit they have to add -0.0322 to the weight.
All the calculation are done in 32-bit while LoRA weigts are trainded.